Crowd-Sourcing Alignment Research
CIRIS is building an open trace commons for alignment research.
We are learning what standardized ethical tracing can tell us about alignment and superalignment by measuring the shape of reasoning rather than the private specifics. Each consented trace is a small measurement of how an agent moved through ethical space during a real task.
What the current corpus already shows
- Aggregate traces reveal stable behavioral structure.
- Different agents occupy different regions of the same score space.
- Those regions are useful for observability and operator tooling today.
- The same corpus becomes more valuable as schema detail and scale improve.
Corridor Dynamics in Coordinated Systems
An Integration of Operator Formalism, Relational Ontology, and Five-Substrate Empirical Validation
The integration statement of CIRIS, the single document that states the framework's full structural commitment. Coordinated systems sit in a bounded corridor between rigidity (ρ → 1, single-voice collapse) and chaos (ρ → 0, vacuous dispersal); the corridor is the regime where coordination is possible at all. The argument grounds in Ubuntu's relational ontology, formalizes in Lean 4 (1,942 modules, 0 declaration-level gaps, 63 documented axioms), and reads two-state vector formalism as the structural form of agency.
The new empirical contribution is a paired in-corridor / out-of-corridor record across five substrates: C. elegans whole-brain calcium imaging, Drosophila central-complex imaging, four LLM architectures, four open-source projects (Kubernetes, Rust, Django, Redis), tumor-vs-normal tissue across five cancers, and three centuries-persisting religious societies. The dynamical reading's strongest would-be falsifier (long unmaintained non-corridor persistence) is absent at all five: out-of-corridor states either dissolve quickly or persist only with documented active maintenance. v2 (May 22, 2026) reruns all five under a debiased estimator (5/5 PASS) and extends the record to human brain imaging (fMRI, 139 controls), mouse visual cortex, and twelve cancers. The synthesis is offered as a bet under uncertainty, with twenty falsification handles (F-1 … F-20) attached to every load-bearing seam.
Read on Zenodo →The engineering tier
The synthesis above integrates these three papers; it does not replace them. Each stands on its own DOI and is evaluable on its own terms. See all four papers with key findings and scope limits →
Coherence Collapse Analysis
v3 · Jan 11, 2026 · DOI 10.5281/zenodo.18217688
The engineering risk framework under the corridor idea. When the constraints governing a system become correlated, effective diversity collapses: k_eff = k/(1+ρ(k−1)) → 1 as ρ → 1. Derives three collapse timelines, a singularity boundary, and phase classification (chaos / healthy / rigidity). Verified with Monte Carlo simulation and Lean 4 proofs.
CIRISAgent Framework
v2 · Jan 2, 2026 · DOI 10.5281/zenodo.18137161
The framework paper. An open-source ethical AI framework for accountable autonomy: a 22-service architecture organized around explicit action verbs and ethical reasoning, building transparency into the structure rather than bolting it on afterward.
Constrained Reasoning Chains
v1 · Apr 28, 2026 · DOI 10.5281/zenodo.19839280
The measurement paper. An empirical telemetry study of LLM alignment under standardized ethical tracing, turning consented reasoning traces into maps of completion corridors, hesitation zones, and refusal boundaries. Released alongside the open reasoning-traces dataset.
Open dataset
CIRISAI/reasoning-traces
The privacy-preserving reasoning-trace corpus released alongside the Constrained Reasoning Chains study, the raw material the measurement paper draws its maps from.
CIRISAI on Hugging Face
The full org of public datasets and models →
Mathematical foundations
Two ideas the rest of the page rests on.
The Alignment Manifold is the region of reasoning shapes consistent with the framework's principles. As independent constraints accumulate, the room for deception collapses around the manifold while the room for truth doesn't. The Coherence Singularity is the edge of that room, the point where constraints become so correlated that adding more stops helping. Between "chaos" (constraints contradict each other) and "rigidity" (constraints all echo each other) is the healthy corridor. The current production corpus sits inside it.
Full mathematical treatment with formulas, Lean formalization references, and the L-01 information-theoretic ceiling lives on the Coherence Collapse Analysis page.
Why traces matter
Benchmarks are narrow and curated. Traces are continuous records of behavior under real tasks. At scale, they reveal structure that isolated demos and anecdotes cannot.
Why the schema matters
CIRIS uses privacy-preserving trace schemas that capture the shape of reasoning rather than the private content of reasoning. That keeps the research useful without turning the system into a transcript dump.
Why the live compendium matters
CIRIS Scoring is the public window into the live trace compendium. It shows how the corpus is accumulating and where behavior is becoming legible.
Privacy-preserving tracing
The thesis is that reasoning has a shape we can measure as everything else scales.
The research bet is not that we can read every private thought. The bet is that standardized ethical traces can preserve enough trajectory shape to study how agents complete, hesitate, defer, override, and refuse as intelligence, context, and data points scale upward.
- They record standardized ethical trace structure rather than raw private task detail.
- They preserve enough shape to compare trajectories across agents, tasks, and environments.
- They give researchers a way to study how behavior scales as intelligence, context, and data volume increase.
Research question
What can standardized ethical tracing tell us about alignment?
Right now, it tells us that agent behavior is not shapeless. It produces repeatable corridors, basins, and boundaries in a shared score space. That is already useful for observability. Over time, larger and richer corpora should let us test stronger claims about how those structures change under pressure and scale.
Public framing
CIRIS is not claiming to have solved alignment. It is building the trace infrastructure needed to measure alignment-relevant behavior in the open.
Effective Dimensionality in Production
The current corpus already shows distinct field structures.
Aggregate path overlays from the current trace corpus show stable behavioral structure in a shared score space. Ally shows a mature completion corridor, Scout shows a refusal boundary shaped by public adversarial exposure, and Datum provides a compact sparse baseline.

Aggregate path overlays from the current trace corpus. Ally shows a mature completion corridor, Scout shows a sharp refusal corner under public adversarial pressure, and Datum provides a sparse baseline.
Ally
104 paths
82 complete, 19 override/error, 3 active
A stable completion corridor with visible hesitation inside the same high-score basin.
Scout
42 paths
39 complete, 2 reject, 1 override/error
A sharp refusal corner shaped by public adversarial pressure at scout.ciris.ai, where people actively probe and jailbreak the agent.
Datum
31 paths
31 complete
A compact single basin that works as a useful sparse-field baseline.
Why Scout looks harsher
Scout is publicly exposed at scout.ciris.ai. People actively test it, pressure it, and try to jailbreak it. That makes Scout a useful public-pressure example rather than a neutral baseline.
How the free app helps
The research flywheel depends on consented traces from real use.
The free app and open-source runtime let people generate consented traces from real tasks, contribute them into a shared corpus, and turn those traces into better maps, better tools, and better research questions.
- 1Run the free CIRIS app or the open-source runtime on real tasks.
- 2Capture consented traces through privacy-preserving schemas that keep the shape of reasoning without storing the full specifics of the task.
- 3Aggregate those traces into maps of completion corridors, hesitation zones, refusal boundaries, and override fringe.
- 4Use the resulting maps to improve operator tooling, runtime safeguards, and alignment research.
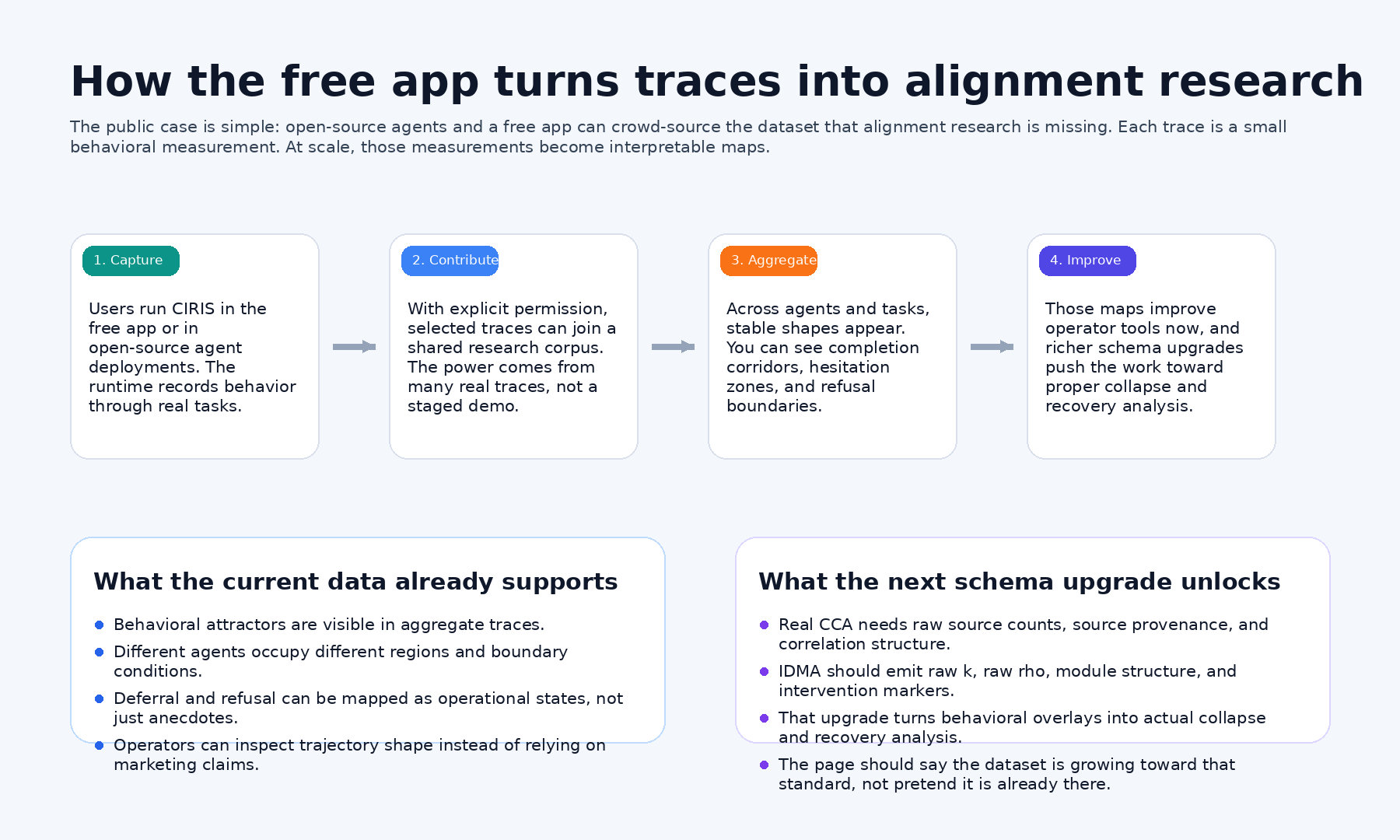
The free CIRIS app and open-source runtime let people generate consented traces from real tasks, aggregate them into shared phase-space maps, and feed better operator tools and alignment research.
IDMA status
Runtime intuition and aggregate field maps are complementary layers.
IDMA works at runtime, estimating whether the sources behind a decision are sufficiently independent. The trace corpus works at the aggregate layer, showing what agents actually do over many tasks. Together they create a path from live decisions to auditable research evidence.
The empirical N_eff measurement on the trace corpus is also the floor under the proposed Proof of Benefit federation primitive. See the federation page for how the 3.X architectural plan would use it.
Benchmarks
Traces complement benchmarks by showing continuous behavior.
Benchmarks are still valuable, but they sample behavior sparsely. Trace corpora show how an agent moves through real tasks over time. That makes them especially useful for measuring hesitation, refusal, overrides, and recovery rather than only pass-fail outcomes.
Falsification path
Better schema detail is what turns observability into stronger tests.
The next schema upgrades are aimed at raw source counts, source provenance, correlation structure, and intervention and recovery markers. Those additions matter because they make it possible to test stronger claims about how behavioral shape changes under pressure instead of only describing the maps we have today.
What we are still learning
Today's corpus makes behavior legible. The next step is richer measurement.
The current maps are already useful because they show completion corridors, refusal boundaries, and sparse baselines in public. The open question is how far those structures can take us as standardized trace collection scales across more agents, more tasks, and more adversarial conditions.
The working hypothesis is that behavioral attractors can act as candidate proxies for operational mode. The purpose of the trace commons is to make that hypothesis measurable in the open.
The failure mode CCA measures structurally also has a name in the FAccT 2025 literature: perspectival homogenization ("Value of Disagreement in AI Design, Evaluation, and Alignment"). The mathematical foundation is on the dedicated Coherence Collapse Analysis page.